
Region-based Convolutional Neural Networks (R-CNN) are a family of machine learning models for computer vision, and specifically object detection and localization.1 The original goal of R-CNN was to take an input image and produce a set of bounding boxes as output, where each bounding box contains an object and also the category (e.g. car or pedestrian) of the object. In general, R-CNN architectures perform selective search2 over feature maps outputted by a CNN.
R-CNN has been extended to perform other computer vision tasks, such as: tracking objects from a drone-mounted camera,3 locating text in an image,4 and enabling object detection in Google Lens.5
Mask R-CNN is also one of seven tasks in the MLPerf Training Benchmark, which is a competition to speed up the training of neural networks.6
History
The following covers some of the versions of R-CNN that have been developed.
- November 2013: R-CNN.7
- April 2015: Fast R-CNN.8
- June 2015: Faster R-CNN.9
- March 2017: Mask R-CNN.10
- December 2017: Cascade R-CNN is trained with increasing Intersection over Union (IoU, also known as the Jaccard index) thresholds, making each stage more selective against nearby false positives.11
- June 2019: Mesh R-CNN adds the ability to generate a 3D mesh from a 2D image.12
Architecture
Selective search
Given an image (or an image-like feature map), selective search (also called Hierarchical Grouping) first segments the image by the algorithm in (Felzenszwalb and Huttenlocher, 2004),14 then performs the following:2
Input: (colour) image
Output: Set of object location hypotheses L
Segment image into initial regions R = {r1, ..., rn} using Felzenszwalb and Huttenlocher (2004)
Initialise similarity set S = ∅
foreach Neighbouring region pair (ri, rj) do
Calculate similarity s(ri, rj)
S = S ∪ s(ri, rj)
while S ≠ ∅ do
Get highest similarity s(ri, rj) = max(S)
Merge corresponding regions rt = ri ∪ rj
Remove similarities regarding ri: S = S \ s(ri, r∗)
Remove similarities regarding rj: S = S \ s(r∗, rj)
Calculate similarity set St between rt and its neighbours
S = S ∪ St
R = R ∪ rt
Extract object location boxes L from all regions in R
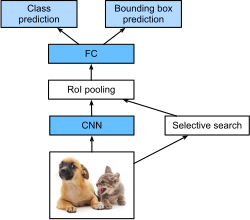
R-CNN
With R-CNN, prediction follows a two-step process. A preprocessing selective search step generates a large set of candidate objects (typically as many as 2000), known as regions of interest (ROI). These are forwarded to a CNN, which predicts an object class score and bounding box estimate, independently for each ROI.
Importantly, the ROIs are heavily filtered to remove excess candidates. This is achieved using two mechanism. Filtering begins by removing ROIs assigned to the background category. This is a specialized category, which is scored by the CNN alongside other categories.
An unfortunate reality is that remaining ROIs typically suffer from heavy duplication. Namely, multiple ROIs that cover same objects in the image are all assigned non-background categories. This is resolved by a heuristic non-maximum suppression15 (NMS) step.
Fast R-CNN
While the original R-CNN independently computed the neural network features on each of as many as two thousand regions of interest, Fast R-CNN runs the neural network once on the whole image.8
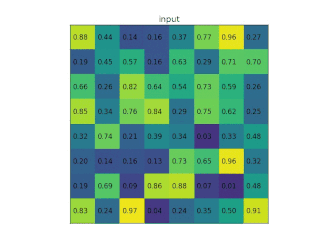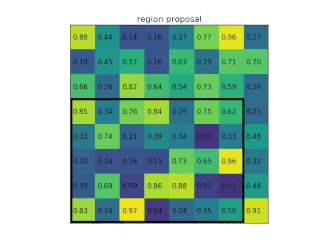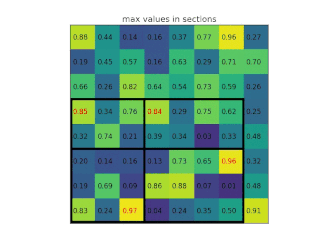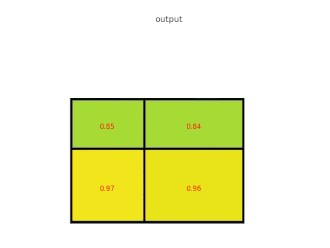
At the end of the network is a ROIPooling module, which slices out each ROI from the network's output tensor, reshapes it, and classifies it. As in the original R-CNN, the Fast R-CNN uses selective search to generate its region proposals.
Faster R-CNN

While Fast R-CNN used selective search to generate ROIs, Faster R-CNN integrates the ROI generation into the neural network itself.9
Mask R-CNN
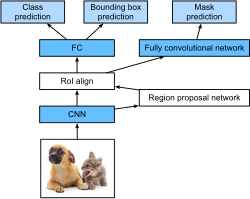
While previous versions of R-CNN focused on object detections, Mask R-CNN adds instance segmentation. Mask R-CNN also replaced ROIPooling with a new method called ROIAlign, which can represent fractions of a pixel.10
References
References
- Zhang, Aston; Lipton, Zachary; Li, Mu; Smola, Alexander J. (2024). "14.8. Region-based CNNs (R-CNNs)". Dive into deep learning. Cambridge New York Port Melbourne New Delhi Singapore: Cambridge University Press. ISBN 978-1-009-38943-3.
- Uijlings, J. R. R.; van de Sande, K. E. A.; Gevers, T.; Smeulders, A. W. M. (2013-09-01). "Selective Search for Object Recognition". International Journal of Computer Vision. 104 (2): 154–171. doi:10.1007/s11263-013-0620-5. ISSN 1573-1405.
- Nene, Vidi (Aug 2, 2019). "Deep Learning-Based Real-Time Multiple-Object Detection and Tracking via Drone". Drone Below. Retrieved Mar 28, 2020.
- Ray, Tiernan (Sep 11, 2018). "Facebook pumps up character recognition to mine memes". ZDNET. Retrieved Mar 28, 2020.
- Sagar, Ram (Sep 9, 2019). "These machine learning methods make google lens a success". Analytics India. Retrieved Mar 28, 2020.
- Mattson, Peter; et al. (2019). "MLPerf Training Benchmark". arXiv:1910.01500v3 [math.LG].
- Girshick, Ross; Donahue, Jeff; Darrell, Trevor; Malik, Jitendra (2016-01-01). "Region-Based Convolutional Networks for Accurate Object Detection and Segmentation". IEEE Transactions on Pattern Analysis and Machine Intelligence. 38 (1): 142–158. Bibcode:2016ITPAM..38..142G. doi:10.1109/TPAMI.2015.2437384. ISSN 0162-8828. PMID 26656583.
- Girshick, Ross (7–13 December 2015). "Fast R-CNN". 2015 IEEE International Conference on Computer Vision (ICCV). IEEE. pp. 1440–1448. doi:10.1109/ICCV.2015.169. ISBN 978-1-4673-8391-2.
- Ren, Shaoqing; He, Kaiming; Girshick, Ross; Sun, Jian (2017-06-01). "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks". IEEE Transactions on Pattern Analysis and Machine Intelligence. 39 (6): 1137–1149. arXiv:1506.01497. Bibcode:2017ITPAM..39.1137R. doi:10.1109/TPAMI.2016.2577031. ISSN 0162-8828. PMID 27295650.
- He, Kaiming; Gkioxari, Georgia; Dollar, Piotr; Girshick, Ross (October 2017). "Mask R-CNN". 2017 IEEE International Conference on Computer Vision (ICCV). IEEE. pp. 2980–2988. doi:10.1109/ICCV.2017.322. ISBN 978-1-5386-1032-9.
- Cai, Zhaowei; Vasconcelos, Nuno (2017). "Cascade R-CNN: Delving into High Quality Object Detection". arXiv:1712.00726 [cs.CV].
- Gkioxari, Georgia; Malik, Jitendra; Johnson, Justin (2019). "Mesh R-CNN". arXiv:1906.02739 [cs.CV].
- Weng, Lilian (December 31, 2017). "Object Detection for Dummies Part 3: R-CNN Family". Lil'Log. Retrieved March 12, 2020.
- Felzenszwalb, Pedro F.; Huttenlocher, Daniel P. (2004-09-01). "Efficient Graph-Based Image Segmentation". International Journal of Computer Vision. 59 (2): 167–181. doi:10.1023/B:VISI.0000022288.19776.77. ISSN 1573-1405.
- Neubeck, A.; Van Gool, L. (August 2006). "Efficient Non-Maximum Suppression". 18th International Conference on Pattern Recognition (ICPR'06). Vol. 3. pp. 850–855. doi:10.1109/ICPR.2006.479. ISBN 0-7695-2521-0.
Further reading
Further reading
- Parthasarathy, Dhruv (2017-04-27). "A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN". Medium. Retrieved 2024-09-11.