Graph neural networks (GNNs) are specialized artificial neural networks that are designed for tasks whose inputs are graphs.12345
One prominent example is molecular drug design.678 Each input sample is a graph representation of a molecule, where atoms form the nodes and chemical bonds between atoms form the edges. In addition to the graph representation, the input also includes known chemical properties for each of the atoms. Dataset samples may thus differ in length, reflecting the varying numbers of atoms in molecules, and the varying number of bonds between them. The task is to predict the efficacy of a given molecule for a specific medical application, such as eliminating E. coli bacteria.
The key design element of GNNs is the use of pairwise message passing, such that graph nodes iteratively update their representations by exchanging information with their neighbors. Several GNN architectures have been proposed,2391011 which implement different flavors of message passing,1213 started by recursive2 or convolutional constructive3 approaches. As of 2022, it is an open question whether it is possible to define GNN architectures "going beyond" message passing, or instead every GNN can be built on message passing over suitably defined graphs.14

In the more general subject of "geometric deep learning", certain existing neural network architectures can be interpreted as GNNs operating on suitably defined graphs.12 A convolutional neural network layer, in the context of computer vision, can be considered a GNN applied to graphs whose nodes are pixels, and only adjacent pixels are connected by edges in the graph. A transformer layer, in natural language processing, can be considered a GNN applied to complete graphs whose nodes are words or tokens in a passage of natural language text.
Relevant application domains for GNNs include natural language processing,15 social networks,16 citation networks,17 molecular biology,18 chemistry,1920 physics21 and NP-hard combinatorial optimization problems.22
Open source libraries implementing GNNs include PyTorch Geometric23 (PyTorch), TensorFlow GNN24 (TensorFlow), Deep Graph Library25 (framework agnostic), jraph26 (Google JAX), and GraphNeuralNetworks.jl27/GeometricFlux.jl28 (Julia, Flux).
Architecture
The architecture of a generic GNN implements the following fundamental layers:12
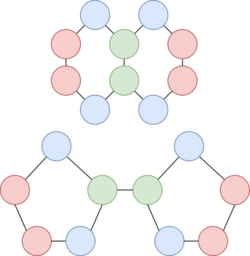
- Permutation equivariant: a permutation equivariant layer maps a representation of a graph into an updated representation of the same graph. In the literature, permutation equivariant layers are implemented via pairwise message passing between graph nodes.1214 Intuitively, in a message passing layer, nodes update their representations by aggregating the messages received from their immediate neighbours. As such, each message passing layer increases the receptive field of the GNN by one hop.
- Local pooling: a local pooling layer coarsens the graph via downsampling. Local pooling is used to increase the receptive field of a GNN, in a similar fashion to pooling layers in convolutional neural networks. Examples include k-nearest neighbours pooling, top-k pooling,29 and self-attention pooling.30
- Global pooling: a global pooling layer, also known as readout layer, provides fixed-size representation of the whole graph. The global pooling layer must be permutation invariant, such that permutations in the ordering of graph nodes and edges do not alter the final output.31 Examples include element-wise sum, mean or maximum.
It has been demonstrated that GNNs cannot be more expressive than the Weisfeiler–Leman Graph Isomorphism Test.3233 In practice, this means that there exist different graph structures (e.g., molecules with the same atoms but different bonds) that cannot be distinguished by GNNs. More powerful GNNs operating on higher-dimension geometries such as simplicial complexes can be designed.343513 As of 2022, whether or not future architectures will overcome the message passing primitive is an open research question.14
Message passing layers
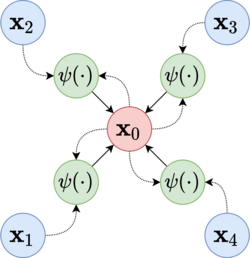
Message passing layers are permutation-equivariant layers mapping a graph into an updated representation of the same graph. Formally, they can be expressed as message passing neural networks (MPNNs).12
Let be a graph, where is the node set and is the edge set. Let be the neighbourhood of some node . Additionally, let be the features of node , and be the features of edge . An MPNN layer can be expressed as follows:12
where and are differentiable functions (e.g., artificial neural networks), and is a permutation invariant aggregation operator that can accept an arbitrary number of inputs (e.g., element-wise sum, mean, or max). In particular, and are referred to as update and message functions, respectively. Intuitively, in an MPNN computational block, graph nodes update their representations by aggregating the messages received from their neighbours.
The outputs of one or more MPNN layers are node representations for each node in the graph. Node representations can be employed for any downstream task, such as node/graph classification or edge prediction.
Graph nodes in an MPNN update their representation aggregating information from their immediate neighbours. As such, stacking MPNN layers means that one node will be able to communicate with nodes that are at most "hops" away. In principle, to ensure that every node receives information from every other node, one would need to stack a number of MPNN layers equal to the graph diameter. However, stacking many MPNN layers may cause issues such as oversmoothing36 and oversquashing.37 Oversmoothing refers to the issue of node representations becoming indistinguishable. Oversquashing refers to the bottleneck that is created by squeezing long-range dependencies into fixed-size representations. Countermeasures such as skip connections1038 (as in residual neural networks), gated update rules39 and jumping knowledge40 can mitigate oversmoothing. Modifying the final layer to be a fully-adjacent layer, i.e., by considering the graph as a complete graph, can mitigate oversquashing in problems where long-range dependencies are required.37
Other "flavours" of MPNN have been developed in the literature,12 such as graph convolutional networks9 and graph attention networks,11 whose definitions can be expressed in terms of the MPNN formalism.
Graph convolutional network
The graph convolutional network (GCN) was first introduced by Thomas Kipf and Max Welling in 2017.9
A GCN layer defines a first-order approximation of a localized spectral filter on graphs. GCNs can be understood as a generalization of convolutional neural networks to graph-structured data.
The formal expression of a GCN layer reads as follows:
where is the matrix of node representations , is the matrix of node features , is an activation function (e.g., ReLU), is the graph adjacency matrix with the addition of self-loops, is the graph degree matrix with the addition of self-loops, and is a matrix of trainable parameters.
In particular, let be the graph adjacency matrix: then, one can define and , where denotes the identity matrix. This normalization ensures that the eigenvalues of are bounded in the range , avoiding numerical instabilities and exploding/vanishing gradients.
A limitation of GCNs is that they do not allow multidimensional edge features .9 It is however possible to associate scalar weights to each edge by imposing , i.e., by setting each nonzero entry in the adjacency matrix equal to the weight of the corresponding edge.
Graph attention network
The graph attention network (GAT) was introduced by Petar Veličković et al. in 2018.11
A graph attention network is a combination of a GNN and an attention layer. The implementation of attention layer in graphical neural networks helps provide attention or focus to the important information from the data instead of focusing on the whole data.
A multi-head GAT layer can be expressed as follows:
where is the number of attention heads, denotes vector concatenation, is an activation function (e.g., ReLU), is the set of immediate neighbor nodes of node , including node itself, are attention coefficients for the -th attention head, and is a matrix of trainable parameters for the -th attention head.
For the final GAT layer, the outputs from each attention head are averaged before the application of the activation function. Formally, the final GAT layer can be written as:
Attention in Machine Learning is a technique that mimics cognitive attention. In the context of learning on graphs, the attention coefficient measures how important node is to node .
Normalized attention coefficients are computed as follows:
where is a vector of learnable weights, indicates transposition, are the edge features (if present), and is a modified ReLU activation function. Attention coefficients are then normalized via softmax to make them easily comparable across different nodes.11
A GCN can be seen as a special case of a GAT where attention coefficients are not learnable, but fixed and equal to the edge weights .
Gated graph sequence neural network
The gated graph sequence neural network (GGS-NN) was introduced by Yujia Li et al. in 2015.39 The GGS-NN extends the GNN formulation by Scarselli et al.2 to output sequences. The message passing framework is implemented as an update rule to a gated recurrent unit (GRU) cell.
A GGS-NN can be expressed as follows:
where denotes vector concatenation, is a vector of zeros, is a matrix of learnable parameters, is a GRU cell, and denotes the sequence index. In a GGS-NN, the node representations are regarded as the hidden states of a GRU cell. The initial node features are zero-padded up to the hidden state dimension of the GRU cell. The same GRU cell is used for updating representations for each node.
Local pooling layers
Local pooling layers coarsen the graph via downsampling. Subsequently, several learnable local pooling strategies that have been proposed are presented.31 For each case, the input is the initial graph represented by a matrix of node features, and the graph adjacency matrix . The output is the new matrix of node features, and the new graph adjacency matrix .
Top-k pooling
We first set
where is a learnable projection vector. The projection vector computes a scalar projection value for each graph node.
The top-k pooling layer 29 can then be formalised as follows:
where is the subset of nodes with the top-k highest projection scores, denotes element-wise matrix multiplication, and is the sigmoid function. In other words, the nodes with the top-k highest projection scores are retained in the new adjacency matrix . The operation makes the projection vector trainable by backpropagation, which otherwise would produce discrete outputs.29
Self-attention pooling
We first set
where is a generic permutation equivariant GNN layer (e.g., GCN, GAT, MPNN).
The Self-attention pooling layer30 can then be formalised as follows:
where is the subset of nodes with the top-k highest projection scores, denotes element-wise matrix multiplication.
The self-attention pooling layer can be seen as an extension of the top-k pooling layer. Differently from top-k pooling, the self-attention scores computed in self-attention pooling account both for the graph features and the graph topology.
Heterophilic Graph Learning
Homophily principle, i.e., nodes with the same labels or similar attributes are more likely to be connected, has been commonly believed to be the main reason for the superiority of Graph Neural Networks (GNNs) over traditional Neural Networks (NNs) on graph-structured data, especially on node-level tasks.41 However, recent work has identified a non-trivial set of datasets where GNN's performance compared to the NN's is not satisfactory.42 Heterophily, i.e., low homophily, has been considered the main cause of this empirical observation.43 People have begun to revisit and re-evaluate most existing graph models in the heterophily scenario across various kinds of graphs, e.g., heterogeneous graphs, temporal graphs and hypergraphs. Moreover, numerous graph-related applications are found to be closely related to the heterophily problem, e.g. graph fraud/anomaly detection, graph adversarial attacks and robustness, privacy, federated learning and point cloud segmentation, graph clustering, recommender systems, generative models, link prediction, graph classification and coloring, etc. In the past few years, considerable effort has been devoted to studying and addressing the heterophily issue in graph learning.414344
Scalability and distributed training
Training GNNs on large graphs presents computational challenges that differ substantially from those in other neural network architectures. Two broad problem settings arise: training on a single very large graph (such as a social network with billions of nodes), and training on collections of large individual graphs (such as molecular systems requiring higher-order interaction modeling).
For the single large graph setting, sampling-based methods reduce memory requirements by operating on subgraphs rather than the full graph. Cluster-GCN partitions the graph into subgraphs using graph partitioning algorithms, training the model on each partition in sequence.45 GraphSAINT instead samples subgraphs stochastically during training, constructing unbiased estimators for the full graph loss.46 Distributed frameworks such as DistDGL47 extend training to multi-machine settings, managing the inter-machine communication required for neighborhood aggregation when a graph's nodes are distributed across machines.
For tasks such as atomic simulations, a different bottleneck arises: GNN architectures that model higher-order interactions between triplets or quadruplets of atoms are memory-intensive at the level of individual graphs, making standard data parallelism — where each GPU processes a separate sample — insufficient when individual graphs exceed single-device memory. Graph Parallelism addresses this by distributing a single input graph across multiple GPUs, partitioning nodes and edges across devices rather than distributing samples across devices.48. This approach enabled GNNs with hundreds of millions to billions of parameters to be trained on atomic systems that would otherwise exceed single-device memory, and has been applied to the development of large-scale universal interatomic potentials.
Applications
Protein folding
Graph neural networks are one of the main building blocks of AlphaFold, an artificial intelligence program developed by Google's DeepMind for solving the protein folding problem in biology. AlphaFold achieved first place in several CASP competitions.495040
Social networks
Social networks are a major application domain for GNNs due to their natural representation as social graphs. GNNs are used to develop recommender systems based on both social relations and item relations.5116
Combinatorial optimization
GNNs are used as fundamental building blocks for several combinatorial optimization algorithms.52 Examples include computing shortest paths or Eulerian circuits for a given graph,39 deriving chip placements superior or competitive to handcrafted human solutions,53 and improving expert-designed branching rules in branch and bound.54
Cyber security
When viewed as a graph, a network of computers can be analyzed with GNNs for anomaly detection. Anomalies within provenance graphs often correlate to malicious activity within the network. GNNs have been used to identify these anomalies on individual nodes55 and within paths56 to detect malicious processes, or on the edge level57 to detect lateral movement.
Water distribution networks
Water distribution systems can be modelled as graphs, being then a straightforward application of GNN. This kind of algorithm has been applied to water demand forecasting,58 interconnecting District Metered Areas(DMAs) to improve the forecasting capacity. Other application of this algorithm on water distribution modelling is the development of metamodels.59
Computer Vision
To represent an image as a graph structure, the image is first divided into multiple patches, each of which is treated as a node in the graph. Edges are then formed by connecting each node to its nearest neighbors based on spatial or feature similarity. This graph-based representation enables the application of graph learning models to visual tasks. The relational structure helps to enhance feature extraction and improve performance on image understanding.60
Text and NLP
Graph-based representation of text helps to capture deeper semantic relationships between words. Many studies have used graph networks to enhance performance in various text processing tasks such as text classification, question answering, Neural Machine Translation (NMT), event extraction, fact verification, etc.61
Atomic simulations and materials science
GNNs have become a primary tool for modeling atomic interactions in computational chemistry and materials science, where molecules and crystal structures are naturally represented as graphs with atoms as nodes and chemical bonds or spatial proximity as edges. A key advantage over traditional quantum chemistry methods such as density functional theory (DFT) is the reduction in computational cost from O(n³) to O(n), enabling simulations at previously impractical scales.
Early GNN architectures for this domain include SchNet (2017), which introduced continuous-filter convolutional layers for learning on 3D molecular structures,62 and DimeNet (2020), which incorporated angular information between atoms to improve geometric expressivity.63 Subsequent equivariant architectures such as NequIP64 and MACE,65 which respect the rotational and translational symmetries of physical systems, achieved significant accuracy improvements on standard benchmarks including QM9, MD17, and the Materials Project.
Large open datasets have driven rapid progress in this area. The Open Catalyst 2020 (OC20) dataset, comprising over 260 million DFT calculations of adsorbate-catalyst surface interactions, established a widely used benchmark for energy and force prediction tasks relevant to catalyst discovery.66. The Materials Project and Alexandria databases have similarly provided large-scale crystal structure data for training universal interatomic potentials. More recent datasets including OMat24 and OMol25 have extended coverage to organic molecules and complex materials at greater computational scale.
These datasets have enabled the development of universal [[machine-learned interatomic potential|machine learning interatomic potentials]] (MLIPs) — models trained across diverse chemical domains rather than on system-specific data. Examples include CHGNet,67 M3GNet,68 MACE-MP, and Meta FAIR's Universal Models for Atoms (UMA), the latter trained on approximately 500 million atomic structures spanning molecules, materials, and catalysts.69 GNoME, developed by Google DeepMind, applied GNNs to predict the stability of crystal structures, reporting the identification of millions of new stable candidate materials.70
References
References
- Wu, Lingfei; Cui, Peng; Pei, Jian; Zhao, Liang (2022). "Graph Neural Networks: Foundations, Frontiers, and Applications". Springer Singapore: 725.
- Scarselli, Franco; Gori, Marco; Tsoi, Ah Chung; Hagenbuchner, Markus; Monfardini, Gabriele (2009). "The Graph Neural Network Model". IEEE Transactions on Neural Networks. 20 (1): 61–80. Bibcode:2009ITNN...20...61S. doi:10.1109/TNN.2008.2005605. ISSN 1941-0093. PMID 19068426. S2CID 206756462.
- Micheli, Alessio (2009). "Neural Network for Graphs: A Contextual Constructive Approach". IEEE Transactions on Neural Networks. 20 (3): 498–511. Bibcode:2009ITNN...20..498M. doi:10.1109/TNN.2008.2010350. ISSN 1045-9227. PMID 19193509. S2CID 17486263.
- Sanchez-Lengeling, Benjamin; Reif, Emily; Pearce, Adam; Wiltschko, Alex (2 September 2021). "A Gentle Introduction to Graph Neural Networks". Distill. 6 (9) e33. doi:10.23915/distill.00033. ISSN 2476-0757.
- Daigavane, Ameya; Ravindran, Balaraman; Aggarwal, Gaurav (2 September 2021). "Understanding Convolutions on Graphs". Distill. 6 (9) e32. doi:10.23915/distill.00032. ISSN 2476-0757. S2CID 239678898.
- Stokes, Jonathan M.; Yang, Kevin; Swanson, Kyle; Jin, Wengong; Cubillos-Ruiz, Andres; Donghia, Nina M.; MacNair, Craig R.; French, Shawn; Carfrae, Lindsey A.; Bloom-Ackermann, Zohar; Tran, Victoria M.; Chiappino-Pepe, Anush; Badran, Ahmed H.; Andrews, Ian W.; Chory, Emma J. (20 February 2020). "A Deep Learning Approach to Antibiotic Discovery". Cell. 180 (4): 688–702.e13. Bibcode:2020Cell..180..688S. doi:10.1016/j.cell.2020.01.021. ISSN 1097-4172. PMC 8349178. PMID 32084340.
- Yang, Kevin; Swanson, Kyle; Jin, Wengong; Coley, Connor; Eiden, Philipp; Gao, Hua; Guzman-Perez, Angel; Hopper, Timothy; Kelley, Brian (20 November 2019). "Analyzing Learned Molecular Representations for Property Prediction". arXiv:1904.01561 [cs.LG].
- Marchant, Jo (20 February 2020). "Powerful antibiotics discovered using AI". Nature. doi:10.1038/d41586-020-00018-3. PMID 33603175.
- Kipf, Thomas N; Welling, Max (2016). "The Graph Neural Network Model". IEEE Transactions on Neural Networks. 20 (1): 61–80. arXiv:1609.02907. Bibcode:2009ITNN...20...61S. doi:10.1109/TNN.2008.2005605. PMID 19068426. S2CID 206756462.
- Hamilton, William; Ying, Rex; Leskovec, Jure (2017). "Inductive Representation Learning on Large Graphs" (PDF). Neural Information Processing Systems. 31. arXiv:1706.02216 – via Stanford.
- Veličković, Petar; Cucurull, Guillem; Casanova, Arantxa; Romero, Adriana; Liò, Pietro; Bengio, Yoshua (4 February 2018). "Graph Attention Networks". arXiv:1710.10903 [stat.ML].
- Bronstein, Michael M.; Bruna, Joan; Cohen, Taco; Veličković, Petar (4 May 2021). "Geometric Deep Learning: Grids, Groups, Graphs Geodesics and Gauges". arXiv:2104.13478 [cs.LG].
- Hajij, M.; Zamzmi, G.; Papamarkou, T.; Miolane, N.; Guzmán-Sáenz, A.; Ramamurthy, K. N.; Schaub, M. T. (2022). "Topological deep learning: Going beyond graph data". arXiv:2206.00606 [cs.LG].
- Veličković, Petar (2022). "Message passing all the way up". arXiv:2202.11097 [cs.LG].
- Wu, Lingfei; Chen, Yu; Shen, Kai; Guo, Xiaojie; Gao, Hanning; Li, Shucheng; Pei, Jian; Long, Bo (2023). "Graph Neural Networks for Natural Language Processing: A Survey". Foundations and Trends in Machine Learning. 16 (2): 119–328. arXiv:2106.06090. doi:10.1561/2200000096. ISSN 1941-0093. S2CID 206756462.
- Ying, Rex; He, Ruining; Chen, Kaifeng; Eksombatchai, Pong; Hamilton, William L.; Leskovec, Jure (2018). Graph Convolutional Neural Networks for Web-Scale Recommender Systems. pp. 974–983. arXiv:1806.01973. doi:10.1145/3219819.3219890. ISBN 978-1-4503-5552-0. S2CID 46949657.
- "Stanford Large Network Dataset Collection". snap.stanford.edu. Retrieved 5 July 2021.
- Zhang, Weihang; Cui, Yang; Liu, Bowen; Loza, Martin; Park, Sung-Joon; Nakai, Kenta (5 April 2024). "HyGAnno: Hybrid graph neural network-based cell type annotation for single-cell ATAC sequencing data". Briefings in Bioinformatics. 25 (3) bbae152. doi:10.1093/bib/bbae152. PMC 10998639. PMID 38581422.
- Gilmer, Justin; Schoenholz, Samuel S.; Riley, Patrick F.; Vinyals, Oriol; Dahl, George E. (17 July 2017). "Neural Message Passing for Quantum Chemistry". Proceedings of Machine Learning Research: 1263–1272. arXiv:1704.01212.
- Coley, Connor W.; Jin, Wengong; Rogers, Luke; Jamison, Timothy F.; Jaakkola, Tommi S.; Green, William H.; Barzilay, Regina; Jensen, Klavs F. (2 January 2019). "A graph-convolutional neural network model for the prediction of chemical reactivity". Chemical Science. 10 (2): 370–377. doi:10.1039/C8SC04228D. ISSN 2041-6539. PMC 6335848. PMID 30746086.
- Qasim, Shah Rukh; Kieseler, Jan; Iiyama, Yutaro; Pierini, Maurizio Pierini (2019). "Learning representations of irregular particle-detector geometry with distance-weighted graph networks". The European Physical Journal C. 79 (7): 608. arXiv:1902.07987. Bibcode:2019EPJC...79..608Q. doi:10.1140/epjc/s10052-019-7113-9. S2CID 88518244.
- Li, Zhuwen; Chen, Qifeng; Koltun, Vladlen (2018). "Text Simplification with Self-Attention-Based Pointer-Generator Networks". Neural Information Processing. Lecture Notes in Computer Science. Vol. 31. pp. 537–546. arXiv:1810.10659. doi:10.1007/978-3-030-04221-9_48. ISBN 978-3-030-04220-2.
- Matthias, Fey; Lenssen, Jan E. (2019). "Fast Graph Representation Learning with PyTorch Geometric". arXiv:1903.02428 [cs.LG].
- "Tensorflow GNN". GitHub. Retrieved 30 June 2022.
- "Deep Graph Library (DGL)". Retrieved 12 September 2024.
- "jraph". GitHub. Retrieved 30 June 2022.
- Lucibello, Carlo (2021). "GraphNeuralNetworks.jl". GitHub. Retrieved 21 September 2023.
- FluxML/GeometricFlux.jl, FluxML, 31 January 2024, retrieved 3 February 2024
- Gao, Hongyang; Ji, Shuiwang Ji (2019). "Graph U-Nets". arXiv:1905.05178 [cs.LG].
- Lee, Junhyun; Lee, Inyeop; Kang, Jaewoo (2019). "Self-Attention Graph Pooling". arXiv:1904.08082 [cs.LG].
- Liu, Chuang; Zhan, Yibing; Li, Chang; Du, Bo; Wu, Jia; Hu, Wenbin; Liu, Tongliang; Tao, Dacheng (2022). "Graph Pooling for Graph Neural Networks: Progress, Challenges, and Opportunities". arXiv:2204.07321 [cs.LG].
- Douglas, B. L. (27 January 2011). "The Weisfeiler–Lehman Method and Graph Isomorphism Testing". arXiv:1101.5211 [math.CO].
- Xu, Keyulu; Hu, Weihua; Leskovec, Jure; Jegelka, Stefanie (22 February 2019). "How Powerful are Graph Neural Networks?". arXiv:1810.00826 [cs.LG].
- Bodnar, Christian; Frasca, Fabrizio; Guang Wang, Yu; Otter, Nina; Montúfar, Guido; Liò, Pietro; Bronstein, Michael (2021). "Weisfeiler and Lehman Go Topological: Message Passing Simplicial Networks". arXiv:2103.03212 [cs.LG].
- Grady, Leo; Polimeni, Jonathan (2011). Discrete Calculus: Applied Analysis on Graphs for Computational Science (PDF). Springer.
- Chen, Deli; Lin, Yankai; Li, Wei; Li, Peng; Zhou, Jie; Sun, Xu (2020). "Measuring and Relieving the Over-Smoothing Problem for Graph Neural Networks from the Topological View". Proceedings of the AAAI Conference on Artificial Intelligence. 34 (4): 3438–3445. arXiv:1909.03211. doi:10.1609/aaai.v34i04.5747. S2CID 202539008.
- Alon, Uri; Yahav, Eran (2021). "On the Bottleneck of Graph Neural Networks and its Practical Implications". arXiv:2006.05205 [cs.LG].
- Xu, Keyulu; Zhang, Mozhi; Jegelka, Stephanie; Kawaguchi, Kenji (2021). "Optimization of Graph Neural Networks: Implicit Acceleration by Skip Connections and More Depth". arXiv:2105.04550 [cs.LG].
- Li, Yujia; Tarlow, Daniel; Brockschmidt, Mark; Zemel, Richard (2016). "Gated Graph Sequence Neural Networks". arXiv:1511.05493 [cs.LG].
- Xu, Keyulu; Li, Chengtao; Tian, Yonglong; Sonobe, Tomohiro; Kawarabayashi, Ken-ichi; Jegelka, Stefanie (2018). "Representation Learning on Graphs with Jumping Knowledge Networks". arXiv:1806.03536 [cs.LG].
- Luan, Sitao; Hua, Chenqing; Lu, Qincheng; Ma, Liheng; Wu, Lirong; Wang, Xinyu; Xu, Minkai; Chang, Xiao-Wen; Precup, Doina; Ying, Rex; Li, Stan Z.; Tang, Jian; Wolf, Guy; Jegelka, Stefanie (2024). "The Heterophilic Graph Learning Handbook: Benchmarks, Models, Theoretical Analysis, Applications and Challenges". arXiv:2407.09618 [cs.LG].
- Luan, Sitao; Hua, Chenqing; Lu, Qincheng; Zhu, Jiaqi; Chang, Xiao-Wen; Precup, Doina (2024). "When do We Need Graph Neural Networks for Node Classification?". In Cherifi, Hocine; Rocha, Luis M.; Cherifi, Chantal; Donduran, Murat (eds.). Complex Networks & Their Applications XII. Studies in Computational Intelligence. Vol. 1141. Cham: Springer Nature Switzerland. pp. 37–48. doi:10.1007/978-3-031-53468-3_4. ISBN 978-3-031-53467-6.
- Luan, Sitao; Hua, Chenqing; Lu, Qincheng; Zhu, Jiaqi; Zhao, Mingde; Zhang, Shuyuan; Chang, Xiao-Wen; Precup, Doina (6 December 2022). "Revisiting Heterophily For Graph Neural Networks". Advances in Neural Information Processing Systems. 35: 1362–1375. arXiv:2210.07606.
- Luan, Sitao; Hua, Chenqing; Xu, Minkai; Lu, Qincheng; Zhu, Jiaqi; Chang, Xiao-Wen; Fu, Jie; Leskovec, Jure; Precup, Doina (15 December 2023). "When Do Graph Neural Networks Help with Node Classification? Investigating the Homophily Principle on Node Distinguishability". Advances in Neural Information Processing Systems. 36: 28748–28760.
- Chiang, Wei-Lin; Liu, Xuanqing; Si, Si; Li, Yang; Bengio, Samy; Hsieh, Cho-Jui (2019). Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 257–266. arXiv:1905.07953. doi:10.1145/3292500.3330925.
- Zeng, Hanqing; Zhou, Hongkuan; Srivastava, Ajitesh; Kannan, Rajgopal; Prasanna, Viktor (2020). GraphSAINT: Graph Sampling Based Inductive Learning Method. International Conference on Learning Representations. arXiv:1907.04931.
- Zheng, Da; Ma, Chao; Wang, Minjie; Zhou, Jinjing; Su, Qidong; Song, Xiang; Gan, Quan; Zhang, Zheng; Karypis, George (2020). DistDGL: Distributed Graph Neural Network Training for Billion-Scale Graphs. Proceedings of the Workshop on Irregular Applications: Architectures and Algorithms (IA³). arXiv:2010.05337.
- Sriram, Anuroop; Das, Abhishek; Wood, Brandon M.; Goyal, Siddharth; Zitnick, C. Lawrence (2022). Towards Training Billion Parameter Graph Neural Networks for Atomic Simulations. International Conference on Learning Representations. arXiv:2203.09697.
- Sample, Ian (2 December 2018). "Google's DeepMind predicts 3D shapes of proteins". The Guardian. Retrieved 30 November 2020.
- "DeepMind's protein-folding AI has solved a 50-year-old grand challenge of biology". MIT Technology Review. Retrieved 30 November 2020.
- Fan, Wenqi; Ma, Yao; Li, Qing; He, Yuan; Zhao, Eric; Tang, Jiliang; Yin, Dawei (2019). Graph Neural Networks for Social Recommendation. pp. 417–426. arXiv:1902.07243. doi:10.1145/3308558.3313488. hdl:10397/81232. ISBN 978-1-4503-6674-8. S2CID 67769538.
- Cappart, Quentin; Chételat, Didier; Khalil, Elias; Lodi, Andrea; Morris, Christopher; Veličković, Petar (2021). "Combinatorial optimization and reasoning with graph neural networks". arXiv:2102.09544 [cs.LG].
- Mirhoseini, Azalia; Goldie, Anna; Yazgan, Mustafa; Jiang, Joe Wenjie; Songhori, Ebrahim; Wang, Shen; Lee, Young-Joon; Johnson, Eric; Pathak, Omkar; Nazi, Azade; Pak, Jiwoo; Tong, Andy; Srinivasa, Kavya; Hang, William; Tuncer, Emre; Le, Quoc V.; Laudon, James; Ho, Richard; Carpenter, Roger; Dean, Jeff (2021). "A graph placement methodology for fast chip design". Nature. 594 (7862): 207–212. Bibcode:2021Natur.594..207M. doi:10.1038/s41586-021-03544-w. PMID 34108699. S2CID 235395490.
- Gasse, Maxime; Chételat, Didier; Ferroni, Nicola; Charlin, Laurent; Lodi, Andrea (2019). "Exact Combinatorial Optimization with Graph Convolutional Neural Networks". arXiv:1906.01629 [cs.LG].
- Wang, Su; Wang, Zhiliang; Zhou, Tao; Sun, Hongbin; Yin, Xia; Han, Dongqi; Zhang, Han; Shi, Xingang; Yang, Jiahai (2022). "Threatrace: Detecting and Tracing Host-Based Threats in Node Level Through Provenance Graph Learning". IEEE Transactions on Information Forensics and Security. 17: 3972–3987. arXiv:2111.04333. Bibcode:2022ITIF...17.3972W. doi:10.1109/TIFS.2022.3208815. ISSN 1556-6021. S2CID 243847506.
- Wang, Qi; Hassan, Wajih Ul; Li, Ding; Jee, Kangkook; Yu, Xiao (2020). "You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis". Network and Distributed Systems Security Symposium. doi:10.14722/ndss.2020.24167. ISBN 978-1-891562-61-7. S2CID 211267791.
- King, Isaiah J.; Huang, H. Howie (2022). "Euler: Detecting Network Lateral Movement via Scalable Temporal Link Prediction" (PDF). In Proceedings of the 29th Network and Distributed Systems Security Symposium. doi:10.14722/ndss.2022.24107. S2CID 248221601.
- Zanfei, Ariele; et al. (2022). "Graph Convolutional Recurrent Neural Networks for Water Demand Forecasting". Water Resources Research. 58 (7) e2022WR032299. AGU. Bibcode:2022WRR....5832299Z. doi:10.1029/2022WR032299. Retrieved 11 June 2024.
- Zanfei, Ariele; et al. (2023). "Shall we always use hydraulic models? A graph neural network metamodel for water system calibration and uncertainty assessment". Water Research. 242 120264. Bibcode:2023WatRe.24220264Z. doi:10.1016/j.watres.2023.120264. PMID 37393807.
- Han, Kai; Wang, Yunhe; Guo, Jianyuan; Tang, Yehui; Wu, Enhua (2022). "Vision GNN: An Image is Worth Graph of Nodes". arXiv:2206.00272 [cs.CV].
- Zhou, Jie; Cui, Ganqu; Hu, Shengding; Zhang, Zhengyan; Yang, Cheng; Liu, Zhiyuan; Wang, Lifeng; Li, Changcheng; Sun, Maosong (1 January 2020). "Graph neural networks: A review of methods and applications". AI Open. 1: 57–81. doi:10.1016/j.aiopen.2021.01.001. ISSN 2666-6510.
- Schütt, Kristof T.; Kindermans, Pieter-Jan; Sauceda, Huziel E.; Chmiela, Stefan; Tkatchenko, Alexandre; Müller, Klaus-Robert (2017). SchNet: A continuous-filter convolutional neural network for modeling quantum interactions. Advances in Neural Information Processing Systems. Vol. 30. arXiv:1706.08566.
- Gasteiger, Johannes; Groß, Janek; Günnemann, Stephan (2020). Directional Message Passing for Molecular Graphs. International Conference on Learning Representations. arXiv:2003.03123.
- Batzner, Simon; Musaelian, Albert; Sun, Lixin; Geiger, Mario; Mailoa, Jonathan P.; Kornbluth, Mordechai; Molinari, Nicola; Smidt, Tess E.; Kozinsky, Boris (2022). "E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials". Nature Communications. 13 (1) 2453. arXiv:2101.03164. Bibcode:2022NatCo..13.2453B. doi:10.1038/s41467-022-29939-5. PMC 9068745. PMID 35508450.
- Batatia, Ilyes; Kovács, Dávid Péter; Simm, Gregor N. C.; Ortner, Christoph; Csányi, Gábor (2022). MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields. Advances in Neural Information Processing Systems. Vol. 35. pp. 11423–11436. arXiv:2206.07697.
- Chanussot, Lowik; Das, Abhishek; Goyal, Siddharth; Lavril, Thibaut; Shuaibi, Muhammed; Riviere, Morgane; Tran, Kevin; Heras-Domingo, Javier; Ho, Caleb; Hu, Weihua; Palizhati, Aini; Sriram, Anuroop; Wood, Brandon; Yoon, Junwoong; Parikh, Devi; Zitnick, C. Lawrence; Ulissi, Zachary (2021). "Open Catalyst 2020 (OC20) Dataset and Community Challenges". ACS Catalysis. 11 (10): 6059–6072. arXiv:2010.09990. doi:10.1021/acscatal.0c04525.
- Deng, Bowen; Zhong, Peichen; Jun, KyuJung; Riebesell, Janosh; Han, Kevin; Barber, Christopher J.; Ceder, Gerbrand (2023). "CHGNet as a pretrained universal neural network potential for charge-informed atomistic modelling". Nature Machine Intelligence. 5 (9): 1031–1041. arXiv:2302.14231. Bibcode:2023NatMI...5.1031D. doi:10.1038/s42256-023-00716-3.
- Chen, Chi; Ong, Shyue Ping (2022). "A universal graph deep learning interatomic potential for the periodic table". Nature Computational Science. 2 (11): 718–728. arXiv:2202.02450. doi:10.1038/s43588-022-00349-3. PMID 38177366.
- Wood, Brandon M.; Dzamba, Misko; Fu, Xiang; Gao, Meng; Shuaibi, Muhammed; Barroso-Luque, Luis; et al. (2025). "UMA: A Family of Universal Models for Atoms". arXiv:2506.23971 [cs.LG].
- Merchant, Amil; Batzner, Simon; Schoenholz, Samuel S.; Aykol, Muratahan; et al. (2023). "Scaling deep learning for materials discovery". Nature. 624 (7990): 80–85. Bibcode:2023Natur.624...80M. doi:10.1038/s41586-023-06735-9. PMC 10700138. PMID 37968396.