| Fisher–Snedecor |
|---|
|
Probability density function 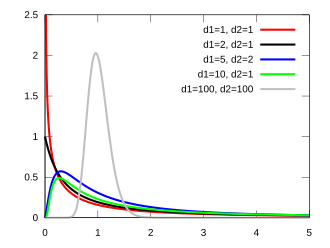 |
|
Cumulative distribution function 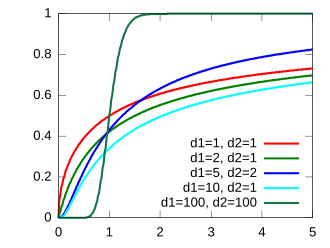 |
| Parameters |
d1, d2 > 0 deg. of freedom |
|---|
| Support |
x ∈ (0, +∞) if d1 = 1, otherwise x ∈ [0, +∞) |
|---|
| PDF |
 |
|---|
| CDF |
 |
|---|
| Mean |
 for d2 > 2 for d2 > 2 |
|---|
| Mode |

for d1 > 2 |
|---|
| Variance |
 for d2 > 4 for d2 > 4 |
|---|
| Skewness |
 for d2 > 6 for d2 > 6 |
|---|
| Excess kurtosis |
see text |
|---|
| Entropy |
 1 1 |
|---|
| MGF |
does not exist, raw moments defined in text and in 23 |
|---|
| CF |
see text |
|---|
In probability theory and statistics, the F-distribution or F-ratio, also known as Snedecor's F distribution or the Fisher–Snedecor distribution (after Ronald Fisher and George W. Snedecor), is a continuous probability distribution that arises frequently as the null distribution of a test statistic, most notably in the analysis of variance (ANOVA) and other F-tests.2345
Definitions
The F-distribution with  and
and  degrees of freedom is the distribution of
degrees of freedom is the distribution of

where  and
and  are independent random variables with chi-square distributions with respective degrees of freedom and .
are independent random variables with chi-square distributions with respective degrees of freedom and .
It can be shown to follow that the probability density function (PDF) for  is given by
is given by
![{\displaystyle {\begin{aligned}f(x;d_{1},d_{2})&={\frac {\sqrt {\frac {(d_{1}x)^{d_{1}}\,\,d_{2}^{d_{2}}}{(d_{1}x+d_{2})^{d_{1}+d_{2}}}}}{x\operatorname {B} \left({\frac {d_{1}}{2}},{\frac {d_{2}}{2}}\right)}}\\[5pt]&={\frac {\left({\frac {d_{1}}{d_{2}}}\right)^{\frac {d_{1}}{2}}{x{\vphantom {\left({d_{1} \over d_{2}}\right)}}}^{{\frac {d_{1}}{2}}-1}\left(1+{\frac {d_{1}}{d_{2}}}\,x\right)^{-{\frac {d_{1}+d_{2}}{2}}}}{\operatorname {B} \left({\frac {d_{1}}{2}},{\frac {d_{2}}{2}}\right)}}\end{aligned}}}](/api/ext/img?url=https%3A%2F%2Fwikimedia.org%2Fapi%2Frest_v1%2Fmedia%2Fmath%2Frender%2Fsvg%2F71c43c71c685d38c397ca5dcf083208971d8b5ce)
for real  . Here
. Here  is the beta function. In many applications, the parameters and are positive integers, but the distribution is well-defined for positive real values of these parameters.
is the beta function. In many applications, the parameters and are positive integers, but the distribution is well-defined for positive real values of these parameters.
The cumulative distribution function is

where  is the regularized incomplete beta function.
is the regularized incomplete beta function.
Properties
The expectation, variance, and other details about the F-distribution  are given in the sidebox; for
are given in the sidebox; for  , the excess kurtosis is
, the excess kurtosis is

The k-th moment of an distribution exists and is finite only when  and it is equal to6
and it is equal to6

The F-distribution is a particular parametrization of the beta prime distribution, which is also called the beta distribution of the second kind.
The characteristic function is listed incorrectly in many standard references (e.g.,3). The correct expression 7 is

where  is the confluent hypergeometric function of the second kind.
is the confluent hypergeometric function of the second kind.
Relation to the chi-squared distribution
In instances where the F-distribution is used, for example in the analysis of variance, independence of  and
and  (defined above) might be demonstrated by applying Cochran's theorem.
(defined above) might be demonstrated by applying Cochran's theorem.
Equivalently, since the chi-squared distribution is the sum of squares of independent standard normal random variables, the random variable of the F-distribution may also be written

where  and
and  ,
,  is the sum of squares of random variables from normal distribution
is the sum of squares of random variables from normal distribution  and
and  is the sum of squares of random variables from normal distribution
is the sum of squares of random variables from normal distribution  .
.
In a frequentist context, a scaled F-distribution therefore gives the probability  , with the F-distribution itself, without any scaling, applying where
, with the F-distribution itself, without any scaling, applying where  is being taken equal to
is being taken equal to  . This is the context in which the F-distribution most generally appears in F-tests: where the null hypothesis is that two independent normal variances are equal, and the observed sums of some appropriately selected squares are then examined to see whether their ratio is significantly incompatible with this null hypothesis.
. This is the context in which the F-distribution most generally appears in F-tests: where the null hypothesis is that two independent normal variances are equal, and the observed sums of some appropriately selected squares are then examined to see whether their ratio is significantly incompatible with this null hypothesis.
The quantity has the same distribution in Bayesian statistics, if an uninformative rescaling-invariant Jeffreys prior is taken for the prior probabilities of and .8 In this context, a scaled F-distribution thus gives the posterior probability  , where the observed sums
, where the observed sums  and
and  are now taken as known.
are now taken as known.
In general
- If
 and
and  (Chi squared distribution) are independent, then
(Chi squared distribution) are independent, then  .
.
- If
 (Gamma distribution) are independent, then
(Gamma distribution) are independent, then  .
.
- If
 (Beta distribution) then
(Beta distribution) then  .
.
- Equivalently, if
 , then
, then  .
.
- If , then
 has a beta prime distribution:
has a beta prime distribution:  .
.
- If then
 has the chi-squared distribution
has the chi-squared distribution  .
.
- is equivalent to the scaled Hotelling's T-squared distribution
 .
.
- If then
 .
.
- If
 – Student's t-distribution – then:
– Student's t-distribution – then: 
- F-distribution is a special case of type 6 Pearson distribution.
- If and
 are independent, with
are independent, with  (Laplace distribution), then
(Laplace distribution), then 
- If
 then
then  (Fisher's z-distribution).
(Fisher's z-distribution).
- The noncentral F-distribution simplifies to the F-distribution if
 .
.
- The doubly noncentral F-distribution simplifies to the F-distribution if

- If
 is the quantile
is the quantile  for and
for and  is the quantile
is the quantile  for
for  , then
, then 
- F-distribution is an instance of ratio distributions.
- W-distribution is a unique parametrization of F-distribution.
See also
See also
References
References
- Lazo, A.V.; Rathie, P. (1978). "On the entropy of continuous probability distributions". IEEE Transactions on Information Theory. 24 (1). IEEE: 120–122. doi:10.1109/tit.1978.1055832.
- Johnson, Norman Lloyd; Samuel Kotz; N. Balakrishnan (1995). Continuous Univariate Distributions, Volume 2 (Section 27) (2nd ed.). Wiley. ISBN 0-471-58494-0.
- Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [June 1964]. "Chapter 26". Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Applied Mathematics Series. Vol. 55 (Ninth reprint with additional corrections of tenth original printing with corrections (December 1972); first ed.). Washington D.C.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. p. 946. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
- NIST (2006). Engineering Statistics Handbook – F Distribution
- Mood, Alexander; Franklin A. Graybill; Duane C. Boes (1974). Introduction to the Theory of Statistics (Third ed.). McGraw-Hill. pp. 246–249. ISBN 0-07-042864-6.
- Taboga, Marco. "The F distribution".
- Phillips, P. C. B. (1982) "The true characteristic function of the F distribution," Biometrika, 69: 261–264 JSTOR 2335882
- Box, G. E. P.; Tiao, G. C. (1973). Bayesian Inference in Statistical Analysis. Addison-Wesley. p. 110. ISBN 0-201-00622-7.
External links
External links